
Comparación, diferencia y significado
Si observamos las medias de los dos conjuntos de datos analizados en el artículo “Medidas de centralidad y dispersión”, podemos comparar la media del conjunto 1 (5,58) con la del conjunto 2 (8,32). Son evidentemente diferentes, pero ¿qué tan diferentes? Otra forma de hacer esta pregunta sería: ¿qué tan fuerte es la posibilidad de que los dos conjuntos de datos (representados por sus medios) realmente representen dos poblaciones diferentes? O, ¿cuál es la probabilidad de que, a pesar de la diferencia de medias, los dos conjuntos de datos realmente provengan de la misma población? [En este contexto, población significa un grupo de sujetos con una característica única]. Otra forma de hacer la pregunta sería establecer una hipótesis inicial, por ejemplo, que las medias para el conjunto 1 y el conjunto 2 son las mismas, que se denomina Hipótesis nula: las medias de ambos conjuntos (poblaciones) son las mismas1.
Una prueba de significancia es un procedimiento estadístico que determina el grado en que los datos observados son consistentes con una hipótesis específica sobre una población. Con frecuencia, a la significancia se le atribuye un valor de probabilidad, por ejemplo, la probabilidad de que los datos observados sean consistentes con la hipótesis es menor que 5 en 100, lo que equivale a <5%. Esta probabilidad se denotaría por “p <0.05”.
Un intervalo de confianza es el resultado de un procedimiento estadístico que identifica el conjunto de todos los valores plausibles de un parámetro específico que son consistentes con los datos observados. Un intervalo de confianza incluye todos los valores posibles de un parámetro que, si se prueba como una hipótesis nula específica (ver más arriba) no nos llevaría a concluir que los datos contradicen esa hipótesis nula en particular.
Haciendo algunas suposiciones sobre la distribución de todos los valores posibles del parámetro (por ejemplo, que los datos del parámetro están distribuidos normalmente; una distribución de frecuencia de todos los datos se aproxima a una forma de campana simétrica) podemos relacionar la probabilidad estadística (valor p) con los intervalos de confianza. Aunque no podemos desarrollar el tema completamente aquí, acepte que para datos distribuidos normalmente la media de los datos ± 1,96 desviaciones estándar de la media (± 1,96 * DE) dividida por la raíz cuadrada del número de observaciones de datos (Ön) incluye 95 % de todos los valores plausibles del parámetro. Por lo tanto, si el valor del parámetro se encuentra dentro del intervalo ± (1,96 DE / Ön), existe una probabilidad de ³ 95% de que el valor contradiga la hipótesis. Para una prueba más estricta, podríamos requerir que la media del valor del parámetro se encuentre dentro de un intervalo de confianza del 99%, que es ± 2.576 DE / Ön de la media. En general, un intervalo de confianza estrecho indica información más precisa sobre el valor del parámetro, mientras que un intervalo amplio indica un mayor grado de incertidumbre.
Comparación de medias
Para comparar las medias y comprobar si son diferentes, la estadística proporciona una serie de pruebas. Por lo general, comenzamos por plantear una hipótesis, por ejemplo, que los medios son en realidad los mismos; a esto lo llamamos la Hipótesis nula. Luego, probamos la probabilidad de que las dos medias sean iguales y que la diferencia informada se deba simplemente al azar; expresamos esta probabilidad como una probabilidad que varía de 0 a 100% (0 a 1). Si la probabilidad de que las medias sean diferentes solo debido a una probabilidad aleatoria es muy pequeña (por ejemplo, menos del 5% (0,05)), entonces la probabilidad de que las medias (y las poblaciones de las que derivan) sean diferentes es mayor. En otras palabras, rechazaríamos la Hipótesis nula como falsa (o extremadamente improbable).
Ejemplos de pruebas estadísticas para comparar medias incluyen la prueba t de Student y el análisis de varianza simple (ANOVA). Si realizamos una prueba t de Student en los conjuntos de datos y probamos la Hipótesis nula (que las dos medias son iguales) al nivel de significancia del 5%, obtenemos un resultado de la prueba de la siguiente manera:
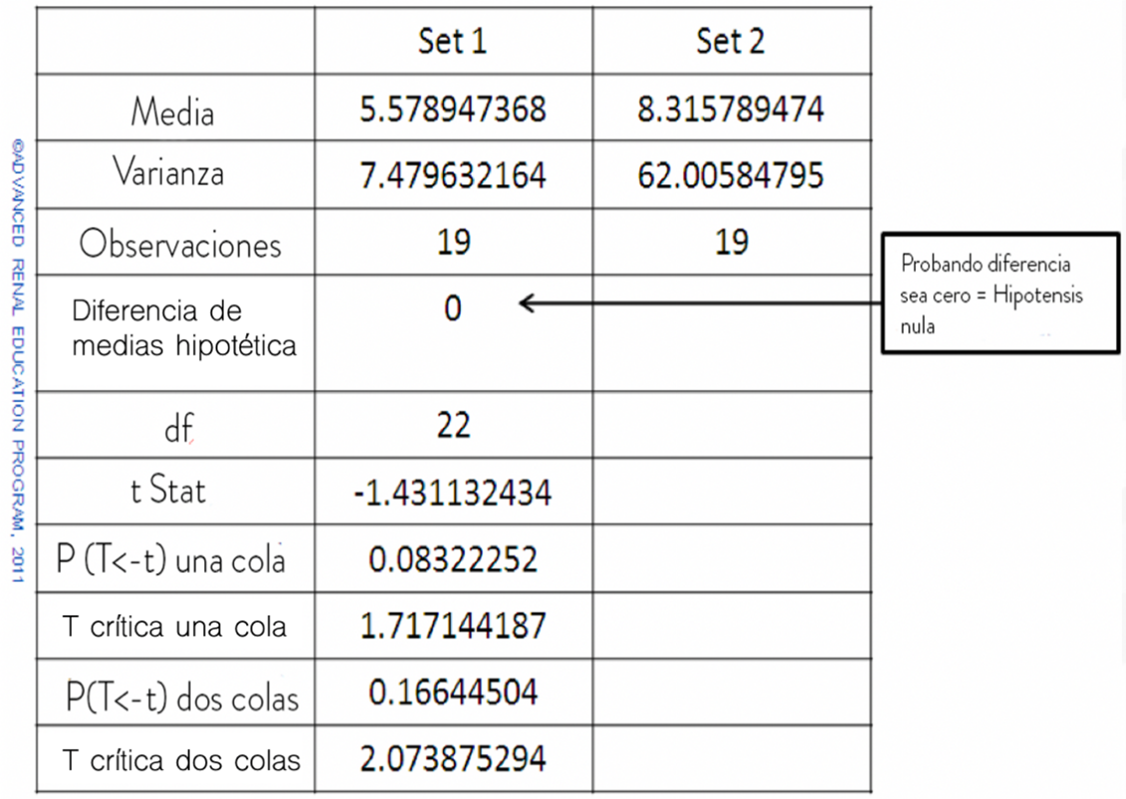
Tenemos la opción de elegir una prueba de una o dos colas: si no asumimos si la media del conjunto 2 es mayor o menor que la del conjunto 1, entonces deberíamos elegir la prueba de 2 colas. Vemos que el valor de p es 0.166, que es mucho mayor que 0.05 (nivel de significancia del 5%). La prueba nos dice que hay evidencia inadecuada para rechazar la Hipótesis Nula y que las medias no son significativamente diferentes. Tenga en cuenta que, si hubiéramos probado que el conjunto medio 2 es mayor que el conjunto medio 1, entonces el valor p (de una cola) sería 0.083, que está mucho más cerca de 0.05 pero aún no es significativo.
Si agregamos otro conjunto, el Conjunto 3, que tiene un valor medio muy cercano al del Conjunto 2, pero arreglamos el conjunto para que tenga una varianza menor, podemos comparar los Conjuntos 1 y 3 usando la misma prueba. Los resultados se muestran a continuación:
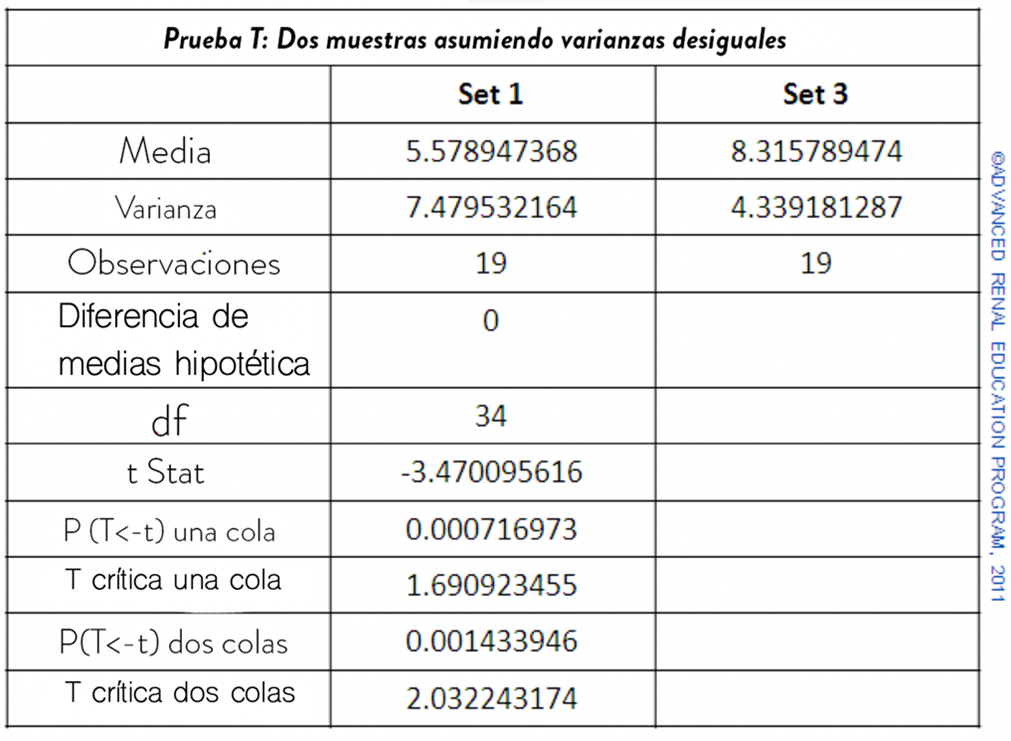
A simple vista, los medios se ven igualmente diferentes a los del ejemplo anterior. Sin embargo, tenga en cuenta que el conjunto de datos 3 tiene una varianza mucho menor que la que vimos para el conjunto 2. Ahora vemos que el valor p (de 2 colas) es 0,0014, que es mucho menor que 0,05. Esto nos dice que solo hay una probabilidad entre 1000 de que las medias sean diferentes por azar. Podemos rechazar la hipótesis nula; los medios son significativamente diferentes.
Si calculamos los intervalos de confianza (IC) del 95% para los conjuntos 1 y 2, encontramos para el conjunto 1 (4,36 a 6,8) y para el conjunto 2 (4,77 a 11,87). Obviamente, el IC del 95% para el conjunto 2 incluye la mayoría de los valores del IC para el conjunto 2, por lo que existe una probabilidad superior al 5% de que los conjuntos de datos provengan de la misma población. Por el contrario, el IC del 95% para el conjunto 3 es (7,38 a 9,26) y no incluye los valores del IC del conjunto 1. Hay menos del 5% de probabilidad de que los datos del conjunto 1 provengan de la misma población que los del conjunto 3.1
Comparar proporciones o distribuciones
Un problema bastante común en la práctica clínica es donde buscamos comparar dos poblaciones por las proporciones en cada una que indican una determinada característica. Un ejemplo serían 100 pacientes asignados al azar para recibir el tratamiento 1 o el tratamiento 2 (50 para cada grupo). El tratamiento se mide como éxito o fracaso. Si el Tratamiento-1 proporciona un 50% de éxito y el Tratamiento 2 un 65% de éxito, ¿son los dos tratamientos realmente diferentes o esta diferencia se debe únicamente al azar?
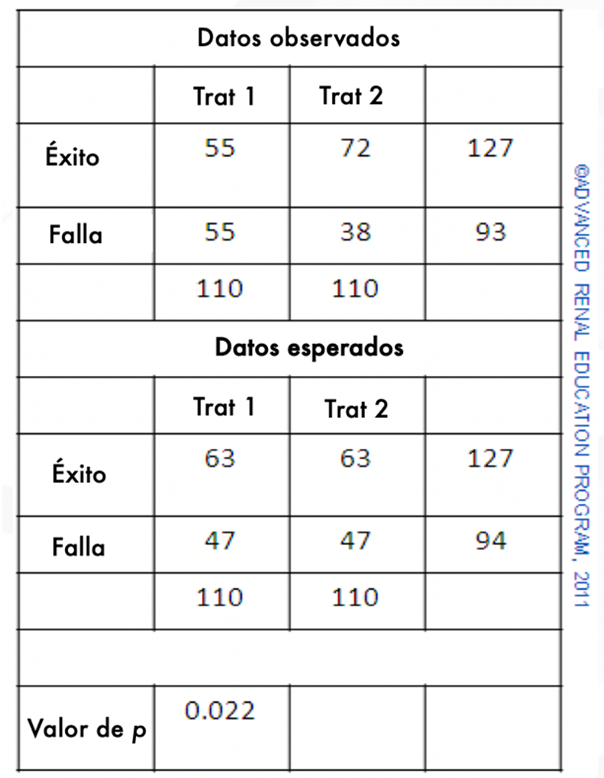
Una vez más, las estadísticas proporcionan varios métodos para comparar los dos tratamientos y proporcionar una medida de la verdadera diferencia. Declaramos la hipótesis nula de que los dos tratamientos son igualmente efectivos y probamos la probabilidad de que esto sea cierto. La prueba de Chi-cuadrado (c2) es un ejemplo de una prueba que resolvería la pregunta planteada por el ejemplo anterior.
Arriba se muestra una ilustración simple de la prueba. Primero registramos los resultados de los tratamientos como se muestra en los datos observados. Para los tratamientos combinados, vemos que hubo un 58% de éxitos y un 42% de fracasos. Luego, configuramos una segunda tabla que atribuye a cada tratamiento estas tasas de éxito y fracaso con los números que hubiéramos esperado si los resultados generales se aplicaran a ambos tratamientos; datos esperados. La prueba de Chi-cuadrado se usa luego para comparar los resultados observados y los resultados esperados y reporta un valor p. El valor p aquí es 0,11, que es mayor que 0,05. La tasa de éxito aparentemente más alta para el Tratamiento 2 se produciría solo por casualidad en el 11% de los ensayos. Los resultados no indican que el Tratamiento 2 sea superior al Tratamiento 1.
En el segundo ejemplo, el número de sujetos en cada grupo aumenta, pero la diferencia en el éxito del tratamiento (aumento del 15%) para el tratamiento 2 en comparación con el tratamiento 1 es proporcionalmente la misma. Ahora vemos que la diferencia es significativa con un valor de p 0.022, que es menor que 0.05. La razón por la que los dos ensayos producen resultados de significancia diferente es similar a la de cuando comparamos las medias anteriores; los números adicionales para este segundo ensayo tienen el efecto de reducir la varianza de los resultados y, por lo tanto, aumentan la importancia de la diferencia.
Los ejemplos aquí de métodos estadísticos para comparar datos y probar si la diferencia detectada se debe solo al azar o es significativa, solo brindan una visión mínima de los posibles métodos disponibles, que son numerosos y pueden usarse para series de datos muy complicadas.
1 These confidence intervals are approximations which assume a completely normal distribution. More accurate CI can be calculated from the data.
Resources
Dawson B, Trapp RG. Chapter 8. Research Questions About Relationships among Variables. In: Dawson B, Trapp RG, eds. Basic & Clinical Biostatistics. 4th ed. New York: McGraw-Hill; 2004.
Walters RW, Kier KL. Chapter 8. The Application of Statistical Analysis in the Biomedical Sciences. In: Kier KL, Malone PM, Stanovich JE, eds. Drug Information: A Guide for Pharmacists. 4th ed. New York: McGraw-Hill; 2012.
Godfrey K. Chapter 6. Testing for Relationships, Reporting Association and Correlation Analyses. In: Lang TA, Secic M, eds. How to Report Statistics in Medicine. 2nd ed. Philadelphia: American College of Physicians; 2006.
P/N 101850-01S Rev B 02/2023