
Regresión
La regresión es similar a la correlación y las dos a menudo se confunden. Los análisis de regresión se utilizan para predecir el valor de una variable en función del conocimiento de otra. Específicamente, la regresión busca construir un modelo matemático que permita predecir el valor de una o más variables dependientes (respuesta) para una variable independiente (explicativa o de estímulo) en particular.
Los modelos de regresión van desde simples univariados (un estímulo y una respuesta) a múltiples (una o más respuestas a más de un estímulo). Los modelos de regresión lineal son aquellos en los que la respuesta cambia de forma lineal. Sin embargo, las respuestas a los estímulos pueden no seguir un camino lineal, pero pueden mostrar un patrón curvilíneo o incluso un patrón parabólico (en forma de U). En algunos casos, la gráfica de los datos de respuesta y estímulo sin procesar muestra una forma curvilínea, pero la transformación de uno o ambos conjuntos de datos puede convertir la relación en una relación lineal (por ejemplo, transformación logarítmica).
Regresión lineal simple
Por ejemplo, en una unidad de hemodiálisis, un médico puede estar interesado en predecir la caída de la PA sistólica (PAS) durante la primera hora de diálisis de acuerdo con la tasa de ultrafiltración aplicada (UFR). El cambio en PAS y UFR se registra durante 33 sesiones de diálisis. Luego, los datos se trazan como un gráfico de dispersión como se ve continuación.
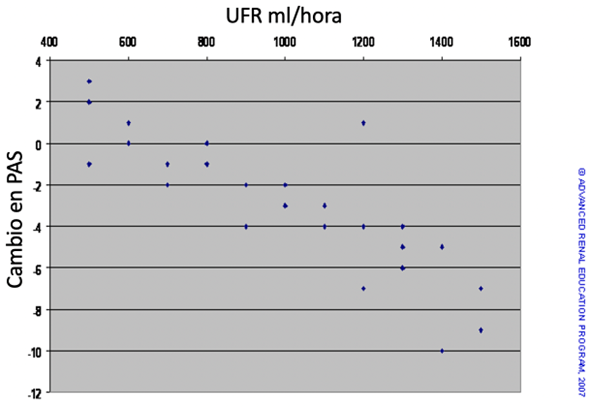
Según el gráfico de dispersión, parece haber una relación negativa (inversa): a medida que aumenta la tasa de UF, la PAS disminuye (es decir, se vuelve más negativa). Usando estadísticas de correlación podemos confirmar esta relación. Sin embargo, nuestro principal interés es poder predecir el grado de caída de la PAS en respuesta a la UF. Mediante un método llamado análisis de mínimos cuadrados, podemos trazar una línea a través de los puntos del gráfico que mejor se ajusten a los datos. Esto es similar a encontrar la “media” para la respuesta de PAS en cada UFR. La línea derivada se muestra en el cuadro a continuación. Esta línea se puede expresar matemáticamente mediante la fórmula Y = bX + a donde “a” es el valor imaginario o real de Y cuando X = 0 ([Y=b*0 + a] = [Y=a]). “b” se denomina coeficiente de regresión, que es la pendiente de la línea de mejor ajuste. Específicamente, “b” representa la cantidad de cambio en Y para cada unidad de cambio en X. Si “b” es negativo, Y cae por cada unidad de aumento en X; si “b” es positivo, Y aumenta por cada unidad de aumento en X.
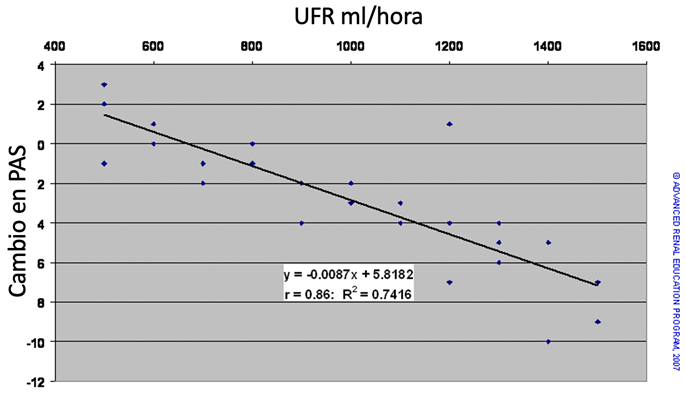
La línea en el gráfico anterior tiene la ecuación Y = -0,0087X + 5,82 (donde Y = cambio en PAS mmHg y X = UFR ml/hora). Este modelo de regresión lineal predice que por cada aumento de UFR en 100 ml/hora, la PAS disminuirá en 0,87 mmHg (100 * 0,0087 = 0,87). El coeficiente de correlación r = -0,86 sugiere que el modelo se ajusta bastante bien a los datos. La estadística también proporciona métodos adicionales para probar la “bondad del ajuste” del modelo; que no necesitamos explorar aquí. Además, el coeficiente de asociación R2 = 0,74 nos dice que el 74% del cambio en la PAS se debe en realidad al cambio en la UFR y el 26% se debe a algún otro efecto no definible en este estudio.
Regresión no lineal
Cuando los datos trazados no asumen una relación lineal, es útil volver a trazar los datos con uno o ambos conjuntos de valores transformados. Se pueden probar varias transformaciones (por ejemplo, usando transformación logarítmica, valores de inversión, valores de potencia, etc.) y la experiencia generalmente informa cuál funcionará mejor. Los resultados del modelo de regresión se pueden volver a convertir al valor normal para derivar las predicciones requeridas. Sin embargo, algunos datos no son lineales y no se pueden convertir ni siquiera con la transformación. A continuación, se muestra un ejemplo.
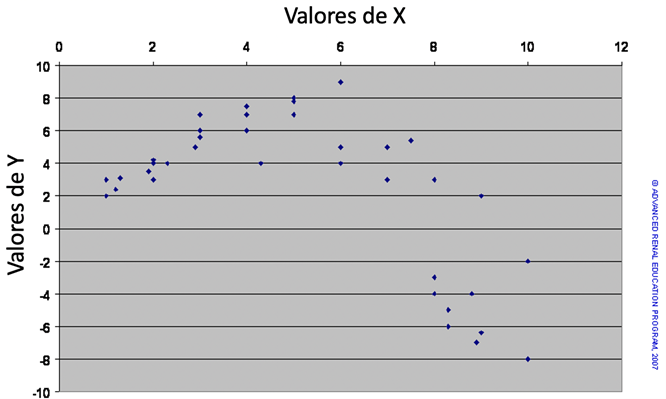
Los valores de X en el gráfico de dispersión anterior representan la dosis de un agente que se sabe que estimula una función metabólica, que se indica mediante los valores de Y. Evidentemente, la relación no es lineal. De hecho, inicialmente, el aumento de la dosis de X mejora la respuesta de Y; sin embargo, por encima de una cierta dosis de X, la respuesta Y parece estar inhibida. Es posible modelar esta regresión no lineal, aunque existen muchos peligros al construir tales modelos.
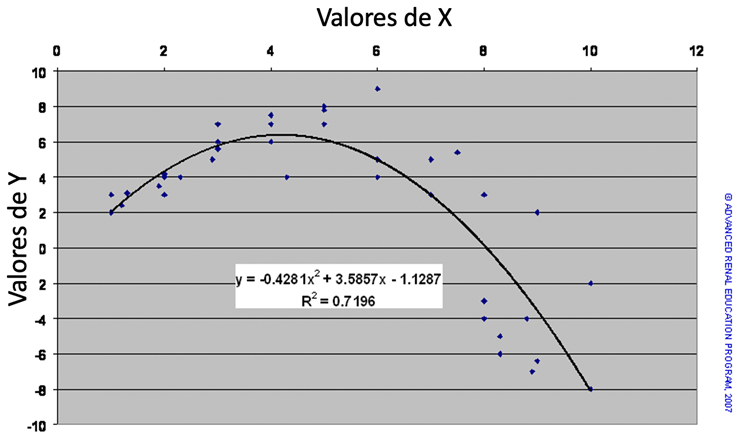
Uno de esos modelos se muestra en el cuadro anterior como una función polinomial. El valor R2 para la regresión ajustada sugiere un buen ajuste, pero esto debería ser probado rigurosamente por métodos estadísticos apropiados.
Regresión logística
¿Cómo podemos modelar la regresión cuando la variable de respuesta es categórica (sí / no: activada / desactivada) en lugar de continua? Los ejemplos incluyen los siguientes: Muerte en respuesta a variables independientes categóricas o continuas. ¿Ser diabético (sí / no) afecta la mortalidad de los pacientes en diálisis? ¿La dosis de diálisis administrada (Kt/V – una variable numérica continua) afecta la tasa de mortalidad? Sería posible medir las tasas de muerte en pacientes diabéticos y no diabéticos y comparar los resultados para indicar un efecto, pero tal método no permitiría una predicción significativa del efecto de la diabetes sobre la muerte.
Para desarrollar un modelo estadístico que permita la predicción cuantificable del efecto de una variable en un evento categórico, se utiliza una técnica llamada Regresión Logística. Las matemáticas son más complejas y no es necesario desarrollarlas aquí. El resultado de los modelos de regresión logística generalmente se expresa como la razón de probabilidades de que el evento categórico ocurrirá de acuerdo con el valor de la variable dependiente (si es una variable continua con una escala numérica) o si la covariable categórica dependiente está presente.
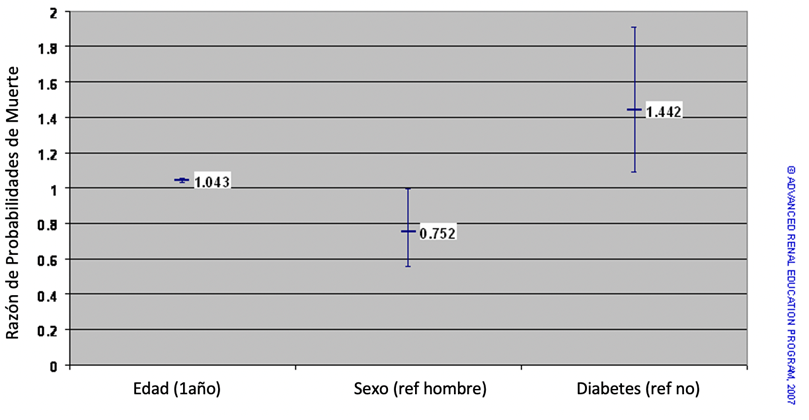
A continuación, se muestra un ejemplo de un análisis de regresión logística. El gráfico muestra el impacto de varios factores demográficos y resultados de laboratorio sobre la muerte de pacientes con EP en los EE. UU. Aquí solo se muestran tres covariables: edad, sexo del paciente y diabetes. La edad es una variable continua que se mide en años. El sexo es una variable categórica, hombre o mujer, y la diabetes es una variable categórica. Observe la forma en que se presentan los datos: cada punto de datos es una barra horizontal con una línea vertical que se extiende por encima y por debajo del punto de datos. Esto se parece a los resultados de la media y la DE que se muestran en la Figura 3, pero no lo es. La barra vertical representa lo que se conoce como intervalo de confianza para la razón de posibilidades.
Si la razón de posibilidades (OR) es mayor que 1, el efecto de un valor aumentado de la variable o la presencia de la covariable es aumentar la probabilidad del evento (muerte en este caso); si es menor que 1, el efecto es reducir la probabilidad del evento. Cuanto más cerca esté el OR del valor 1, menor será el efecto; un OR de 1 indica que no hay efecto. La estadística informa el OR y un intervalo de confianza (IC) para el OR. Por ejemplo, para la diabetes en el ejemplo anterior, el OR es 1,44 y el intervalo de confianza del 95% es de 1,09 a 1,9. Dicho de otra manera, la razón de probabilidades estimada de muerte para los diabéticos en comparación con los no diabéticos es de 1,44, y hay un 95% de certeza de que el OR real se encuentra entre 1,09 y 1,9. Debería ser evidente que, si el IC del 95% incluye el valor 1, entonces existe la posibilidad de que no haya efecto. Por tanto, podemos afirmar que, si el IC del OR incluye el valor 1, el efecto detectado no es significativo.
La figura anterior muestra que, por cada año adicional de edad, el OR de muerte es 1.043. El intervalo de confianza (1.032 a 1.055) no incluye 1; la barra vertical no cruza la línea del valor 1. Otra forma de expresar esto sería afirmar que, por cada año adicional de edad, las probabilidades de morir aumentan en un 4.3% (1.043 = 1 + 0.043: 0.043 = 4,3%). Las mujeres (en comparación con los hombres) tienen un 25% menos de probabilidades de morir (1 – 0,75 = 0,25 x 100% = 25%; tenga en cuenta, sin embargo, que la parte superior de la barra de IC se acerca mucho a 1 (IC real = 0,56 a 0,99) por lo que la significación de este OR es menor, por otro lado, tener diabetes aumenta las probabilidades de morir en un 44% (OR = 1,44) y la barra vertical del IC se aleja de 1.
La regresión logística también construye un modelo predictivo para el evento que incorpora aquellas variables y covariables que tienen una significación estadística. La ecuación del modelo tiene la forma básica Y = bx + a que vimos anteriormente para la regresión lineal. En el ejemplo de la Figura 8 hay tres variables, por lo que el modelo se vería así: Y = b1x1 + b2x2 + b3x3 + a. Con los valores de los tres coeficientes, b1 a 3, pudimos predecir el efecto combinado de las tres variables sobre las probabilidades de muerte. Además, el método estadístico proporcionaría medidas de bondad de ajuste para el modelo.
Referencias:
Dawson B, Trapp RG. Chapter 8. Research Questions About Relationships among Variables. In: Dawson B, Trapp RG, eds. Basic & Clinical Biostatistics. 4th ed. New York: McGraw-Hill; 2004.
Walters RW, Kier KL. Chapter 8. The Application of Statistical Analysis in the Biomedical Sciences. In: Kier KL, Malone PM, Stanovich JE, eds. Drug Information: A Guide for Pharmacists. 4th ed. New York: McGraw-Hill; 2012.
Godfrey K. Chapter 6. Testing for Relationships, Reporting Association and Correlation Analyses. In: Lang TA, Secic M, eds. How to Report Statistics in Medicine. 2nd ed. Philadelphia: American College of Physicians; 2006.
P/N 101852-01S Rev B 02/2023